AMD正在探索如何在晶片上堆疊L2快取以獲得更低延遲
发布时间:2026-04-24 来源:多快好省网作者:地狱的眼泪alex
 第二代 3D V-Cache
第二代 3D V-Cache
AMD 新發表了一篇題為「平衡延遲堆疊式快取」的研究論文,探討未來晶片上堆疊 L2 快取的方法,同時盡可能提供更低的延遲,該論文專利註冊號是 US20260003794A1。
目前大家所熟知的堆疊式快取便是 AMD 推出的 3D V-Cache,運用矽通孔連接主體運算晶片和快取記憶體。
現在的第 2 代 3D V-Cache 把快取記憶體墊在主體運算晶片和基板之間,藉此提高主體運算晶片的散熱效率,已應用於 Ryzen 9000X3D 系列消費級處理器與特定 EPYC 資料中心處理器,都顯著增加 L3 快取容量。
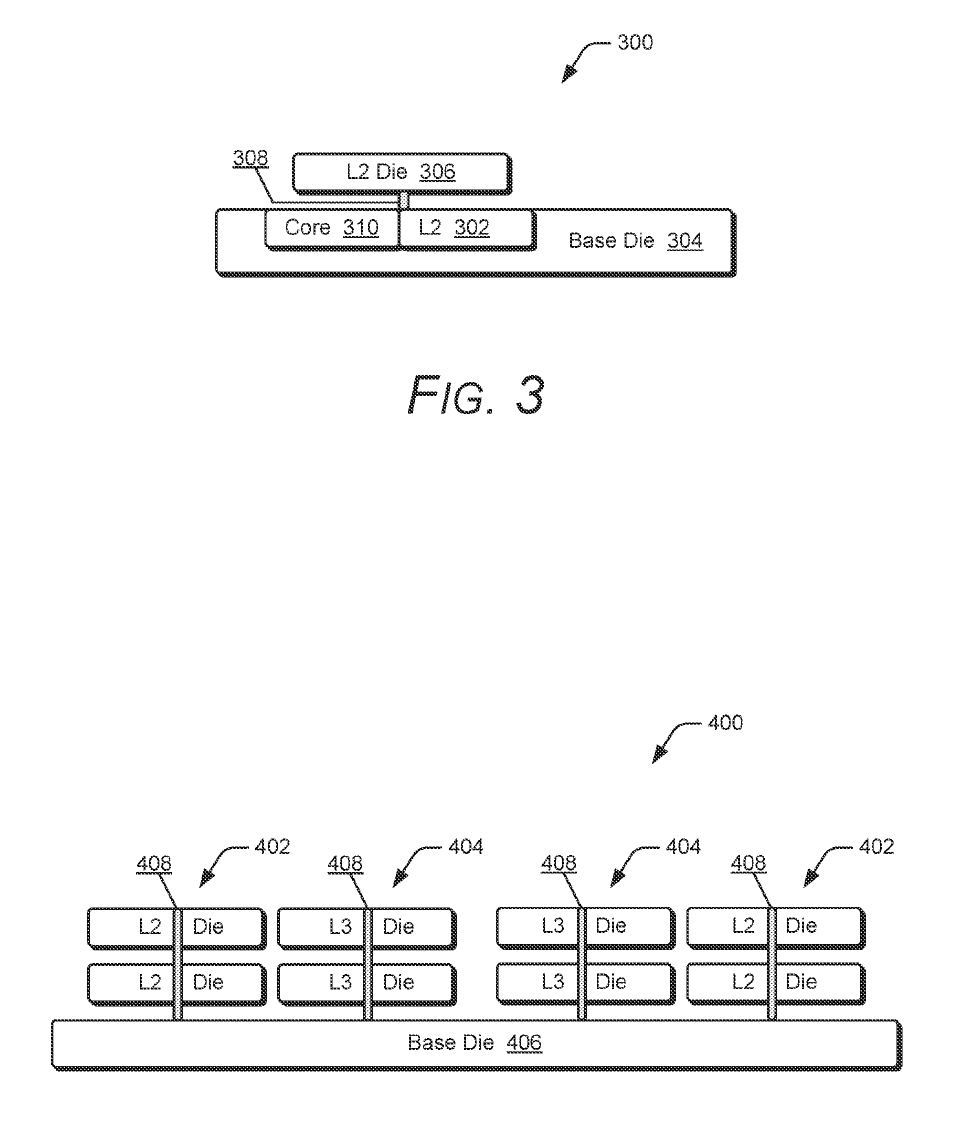
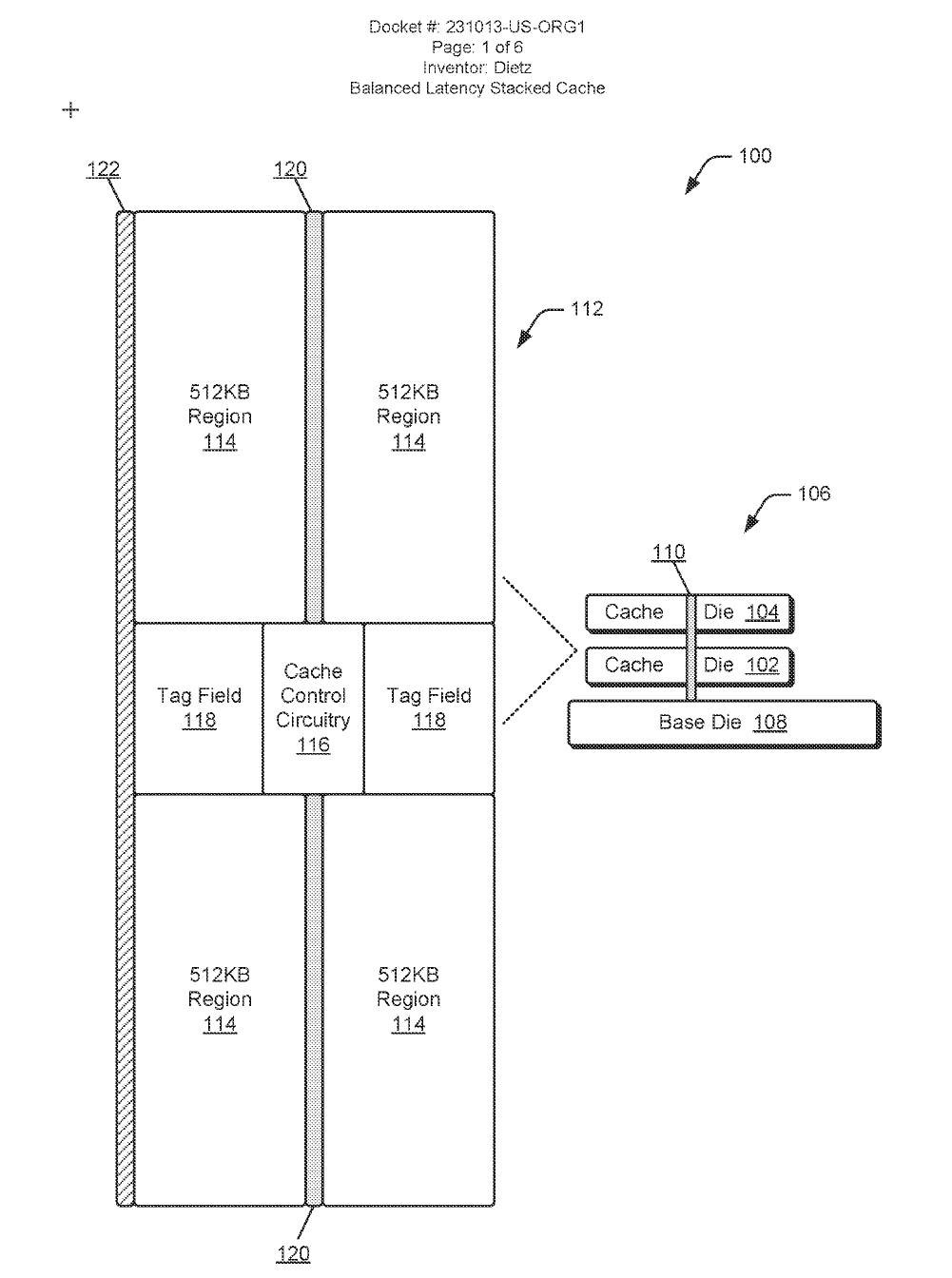
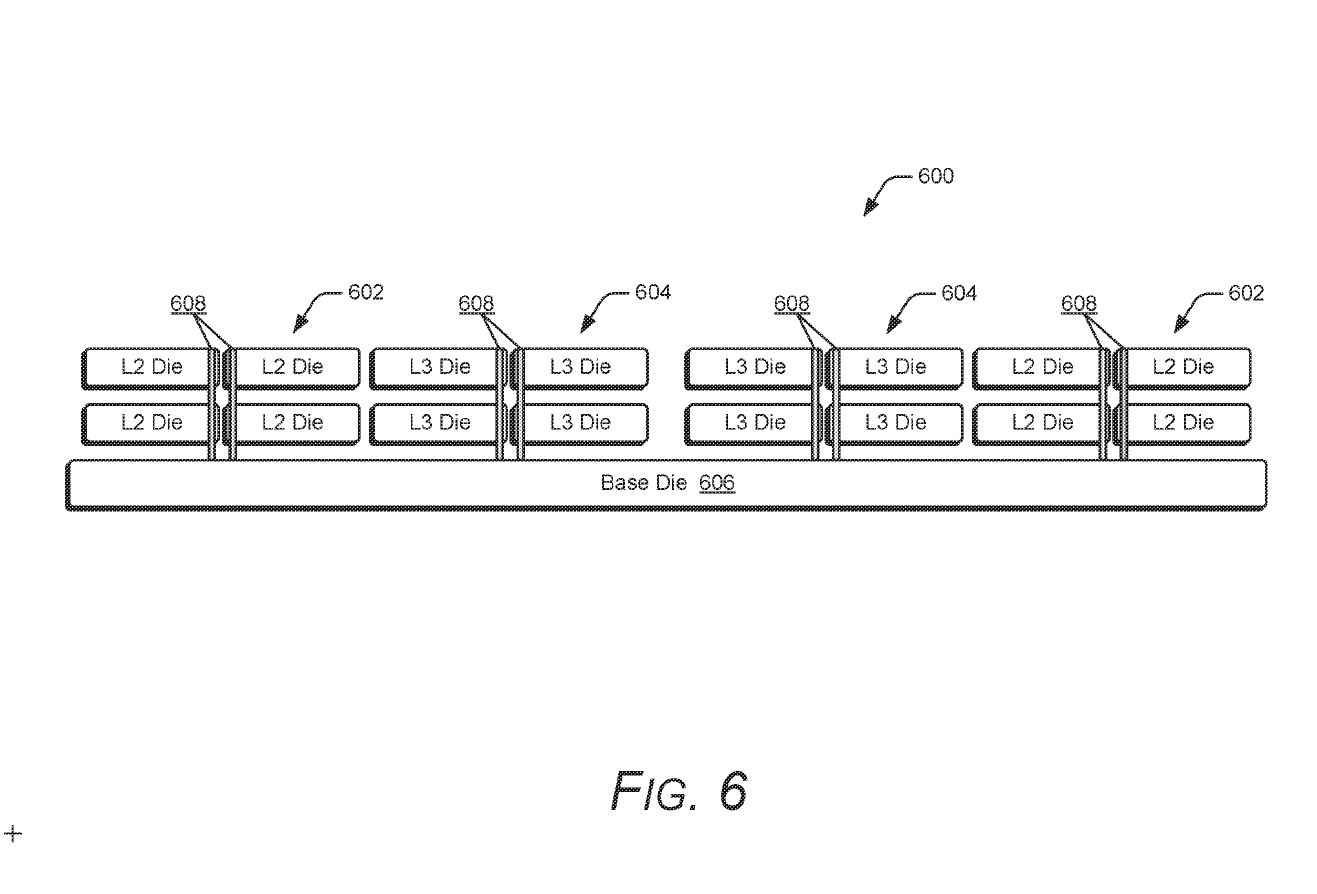
AMD 打算把這個技術延伸到 L2 快取,專利說明範例中堆疊式的 L2 快取包含 4 個 512KB 區塊,組合成 2MB 的 L2 堆疊快取,最大可擴展至 4MB。
AMD 在論文中指出,由於堆疊式快取集中在基礎晶片的上方,相較於需要另外安排額外佈線的平面式快取擁有更小的物理距離,延遲也會更低。
一般來說,平面式 1MB L2M 快取的典型延遲為 14 個時脈週期,而堆疊式 1MB L2M 快取的延遲可縮小至 12 個時脈週期,略優於平面式快取。
另一方面由於存取週期縮短,同步減少快取單元的啟用時間,快取便可更快從運作狀態切換至閒置狀態,再加上佈線短同時帶來訊號負載降低,兩種特性都能進一步降低功耗。
AMD 並未說明何時能實現堆疊式 L2 技術,總之我們拭目以待。
- 上一篇:{loop type="arclist" row=1 }{$vo.title}